Research
Research topics
Living in an uncertain environment, we desire to pursue good things and to avoid bad things. We are interested in how the brain recognizes different situations and learns to make better decisions. Related questions are: How does the brain represent sensory information? How does the brain represent reward or punishment? How does the brain associate external sensory or internal state information with value? How does the brain choose one action out of multiple options? How does the brain control vigor of actions? See more detailed information below.

Keyword visualization using TagCrowd based on recent abstracts
Diverse research topics in the lab can be represented in a four-dimensional space: 1) valence (good vs. bad), 2) timescale of activity (days of learning vs. seconds of dynamics), 3) normal brain vs. abnormal brain, and 4) focusing on biological brain (e.g., neural circuits) vs. computational principles. This is not exclusive; people study, for example, both good and bad / both biological and computational aspects.
- KSBNS 2024 NeuRLab abstracts, for those who want to peek ongoing works.
- A lab introduction interview on the SKKU webzine (Korean, posted 2023. 12. 22).
- Journal club and lab meeting list
Investigating the neural basis of reinforcement learning

How do we learn whether something is good or bad? When something is better or worse than we expected, our brain generates a ‘teaching signal’ to change behaviors. The activity of dopamine, one of the neuromodulators in the brain, has been believed to reflect this teaching signal. Experiments using animals show that manipulating dopamine activity in the brain can affect animals’ choice behaviors.
In machine learning, computer scientists have studied how a program in a virtual world, an agent, can obtain maximum reward in a virtual environment (e.g., PAC-MAN). Reinforcement learning theory studies teaching signals in a mathematical and normative manner - it provides a ‘sure’ answer to this problem. If an agent follows a specific learning rule, the agent is guaranteed to achieve the goal - maximizing reward. Recently, reinforcement learning algorithms that incorporated deep neural networks have shown amazing performance in many tasks.
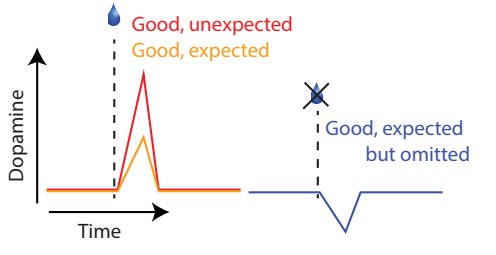
Interestingly, it has been shown that phasic dopamine activity in the brain happens to resemble the activity of the teaching signal in one of reinforcement learning theories, temporal difference learning. Moreover, HyungGoo’s postdoctoral work demonstrated that the brain computes moment-by-moment temporal difference error signals (see below).
However, we do not know 1) how such teaching signals are computed, and 2) how such teaching signals change the networks in the brain. We perform experiments using animals and analyze data using computational models to understand the biological mechanisms of reinforcement learning.
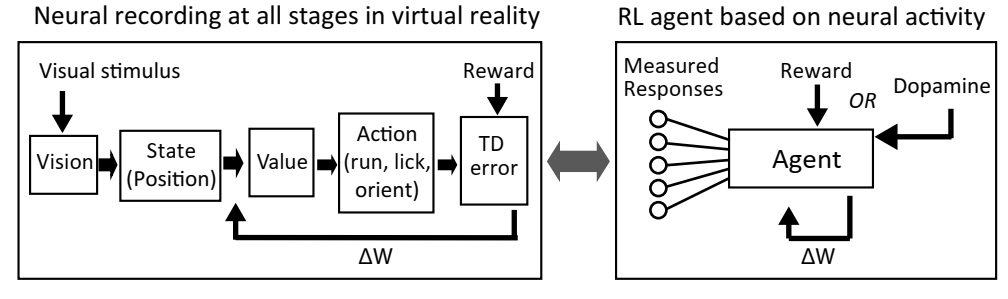
Once we get some insights, we plan to use simulation environment to implement brain-insipired agents and compare the performance with contemporary machine learning agents. One advantage of using virtual reality is that we can train an artificial agent with visual stimuli that are identical to what animals see during the experiments. Below is an example of RL agent performing a approach-to-reward task.
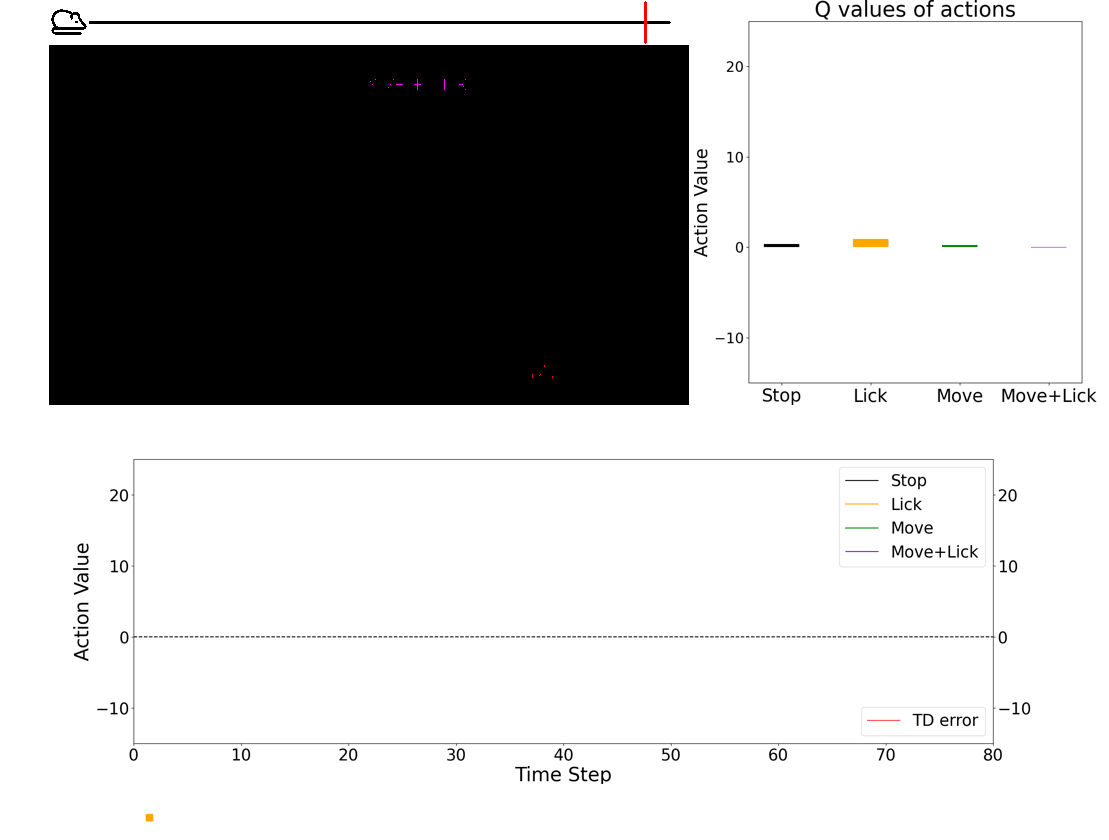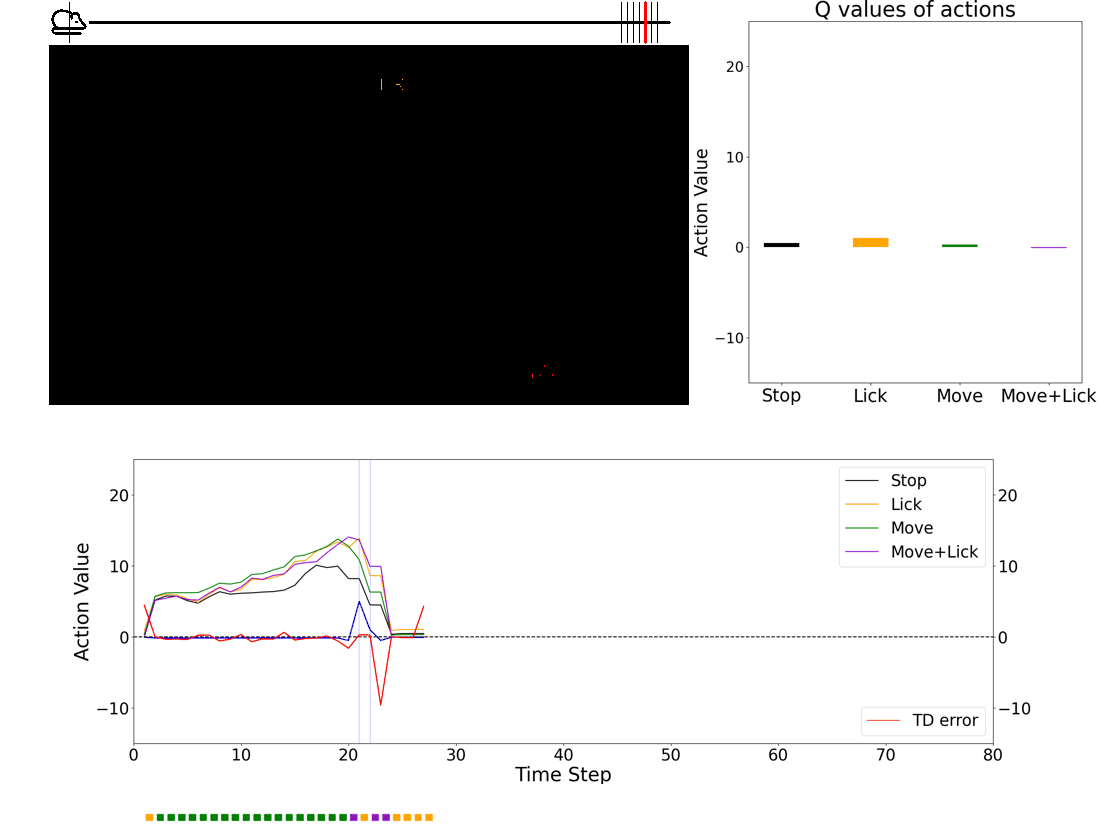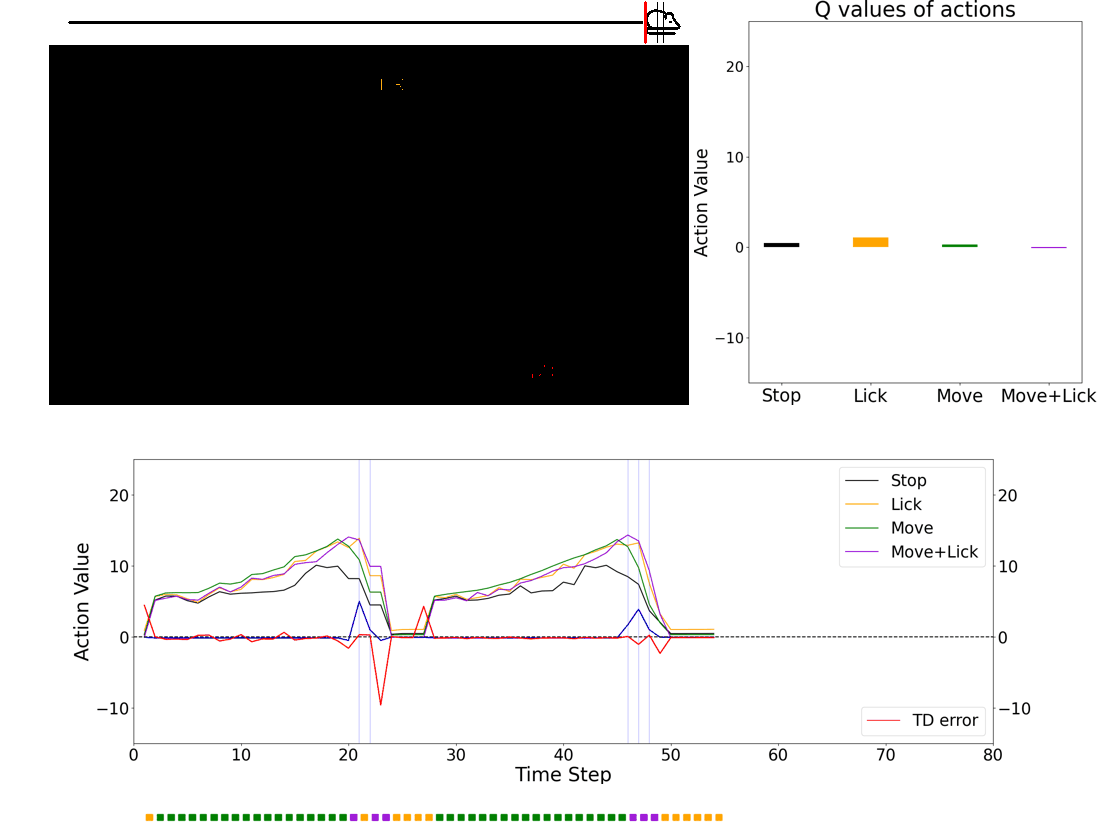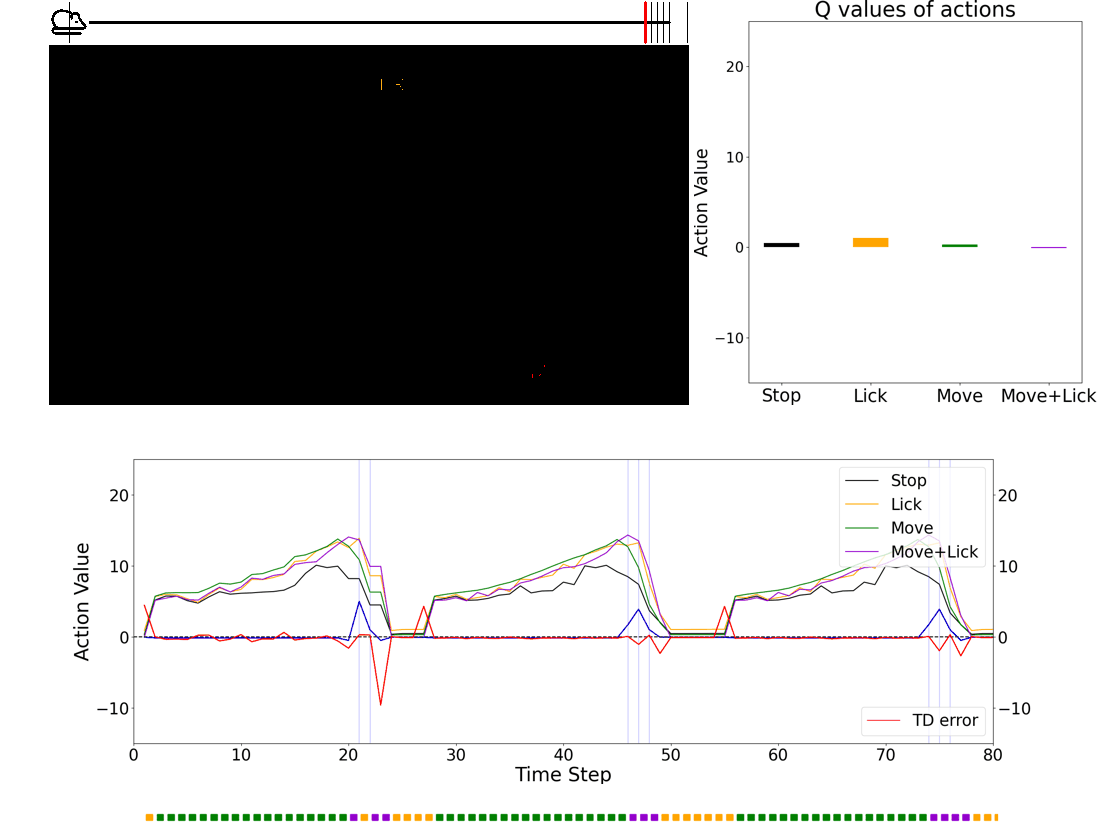
Investigating the role of neuromodulators in uncertain environments
In real environments with different types of uncertainties, neuromodulators other than dopamine are involved in guiding adaptive behaviors. But the measurement of neuromodulators has not been very easy. Recently, new biosensors have been developed and provide exciting opportunities to monitor various neuromodulators. We plan to monitor the activities of non-dopamine neuromodulators in the brain and to understand how these molecules affect emotion, motivation, and behavior.
Investigating neural reinforcement learning dealing with more complicated situations in non-human primates
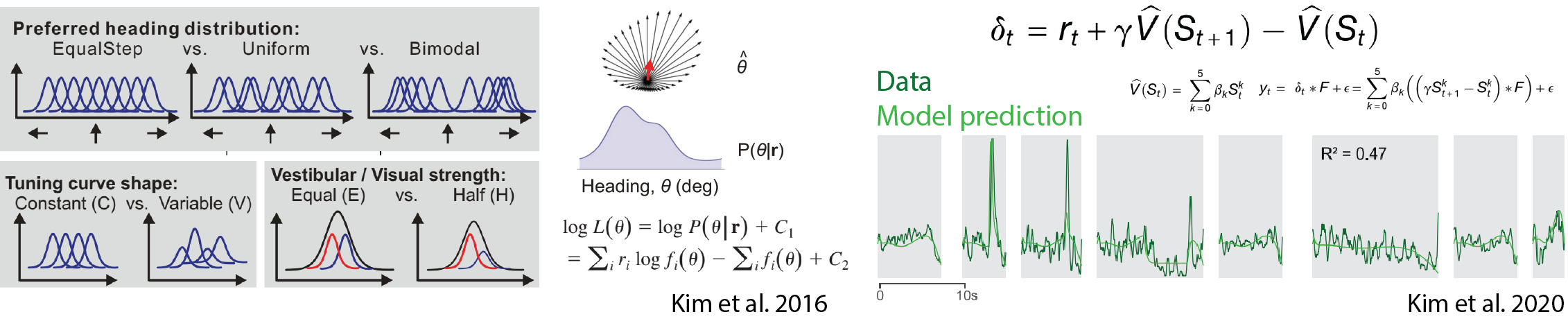
Usually, we have multiple options in life, and good and bad events happen in a probabilistic manner. Animals with higher cognitive intelligence such as non-human primates have evolved to process more complex information and learn fast and flexibly. We aim to understand the underlying mechanisms by developing a variety of cognitive tasks in NHPs. One research direction is distributional reinforcement learning, the notion that the brain represents values or other reinforcement learning parameters in a distributional manner.
Another potential direction is cross-species comparison. We know that humans are smarter than monkeys. We know that monkeys are smarter than mice. But why? In addition to the difference in size, previous studies have shown fundamental differences in the anatomical and physiological properties of neurons. In addition to this, we would like to understand whether and how the neural computations differ between mice and monkeys. By extrapolating the difference, we may understand (whether and) how humans are unique in their intellectual performance.
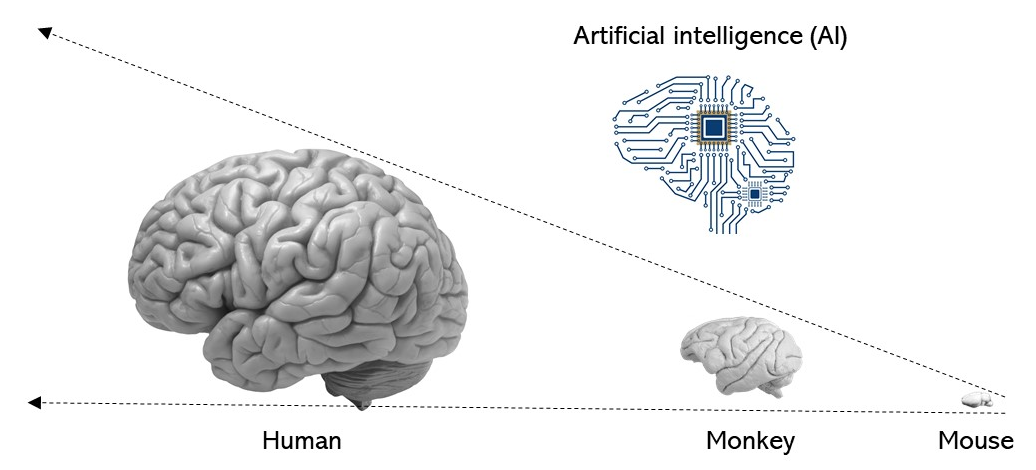
Understanding human intelligence by examining difference between mice and monkeys in combination with computational modeling.
Approaches
Here we highlight some of our scientific approaches.
 |
- 🐁 Simple cognitive tasks for rodents in a real environment or virtual reality
- 🐁 Cell-type-specific or target-specific monitoring or optogenetic manipulations in rodents
- 🐵 Complex cognitive tasks for non-human primates in 2D or 3D environments, using a joystick and/or eye movement as motor inputs.
- 🐁🐵 Large-scale electrophysiological recording (big data neuroscience)
- 💻 Computational modeling using artificial neural network
- 🐁🐵 Comparing similarity and difference between species(Cross-species neuroscience)
By doing this, we hope to understand human nature, to help treat malfunctions of the brain, and to apply the principle of learning to improve artificial intelligence. Specifically, we are interested in using virtual reality to thoroughly examine the malfunction of dopamine circuitry in animal models of mental illness such as addiction.
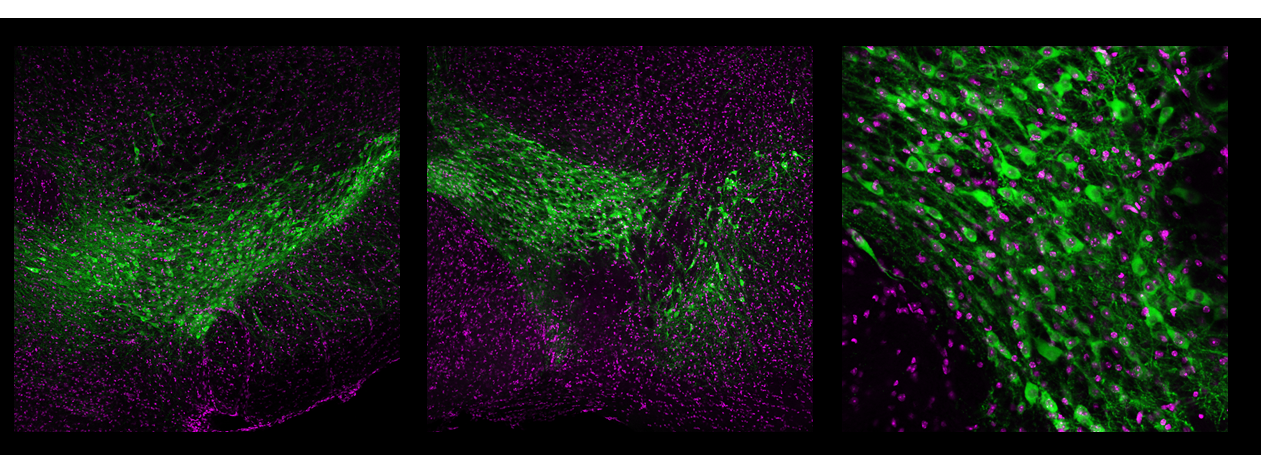
Dopamine neurons play important roles in learning, movtivation, and movement. Images courtesy of Ryu Amo.
Past works
Graduate work in non-human primates 🐵
My graduate work addressed questions about how neurons in the sensory cortex represent the depth of visual stimuli, and how such neural responses are used by downstream areas for perceptual decision making. Specifically, when we move in space, the change of viewing position causes apparent motion of stationary objects, which can be used by the brain to estimate depth (motion parallax). I focused on motion parallax since the neural mechanisms of perception based on it were largely unknown.
I provided the first demonstration that global patterns of visual motion can disambiguate depth from motion parallax, provided the first direct comparison of neural and behavioral sensitivity in the context of perceiving depth from motion parallax, demonstrated a mechanism by which extra-retinal signals modulate visual responses to signal depth, and provided a general computational framework for performing marginalization using linear population decoding.
Postdoctoral work in mice 🐁
Paper; An essay posted on the Harvard MCB department webpage
The neurotransmitter dopamine is implicated in learning, motivation, and movement. These variables are often modulated on a similar timescale, which makes it difficult to separate them from one another. One important example of controversy in the field involves ‘ramping’ dopamine signals. While rats approached a reward location in a maze, dopamine activity gradually ramped up1. Several authors argued that ramping dopamine encodes the expectation of future reward, which is called ‘value’, a greater value indicating the higher expectation of reward.
This argument is, however, not compatible with the alternative, widely accepted model. The activity of dopamine neurons have been hypothesized to reflect the difference between value at the current time and the value the animal had in mind right before, or the ‘slope’ of the value function, called ‘temporal difference error (TD error)’. TD error signals can gradually increase if the value function gets steeper as the animal gets closer to a reward.
Interestingly, some machine learning algorithms use TD errors to update value. Note that algorithms work only if the TD error is computed all the time even before the animal obtains a reward (i.e., in a moment-by-moment manner). It has not been tested, however, whether dopamine activity in the brain has this property or not. If the ramping dopamine activity turned out to be TD errors, it would be undeniable evidence that the brain computes this teaching signal in a way similar to the one in the machine learning algorithm.
How can we distinguish whether dopamine activity is value or TD error? Imagine that an animal is approaching a reward location but is suddenly teleported to a location closer to the reward. If value depends on the animal’s position, value would show a step-like increase at the time of teleportation. In contrast, since the step-like increase happens in a very short time, TD error would show a transient excitation at the time of teleportation. The magnitude of the transient excitation would depend on the distance teleported. Additionally, the value would stay constant if the position of the animal stays constant temporarily, whereas a TD error would decrease back to baseline as there is no change of value in time.
The question is, how can we teleport an animal? I developed a visual virtual reality and a series of novel experimental paradigms to manipulate the animal’s position and examine the nature of dopamine ramping signals. Surprisingly, all of the experimental results were consistent with dopamine activity encoding TD errors, not value (see Kim et al. Fig. 2 for results from other experiments). This powerful experimental setup forms the basis for my future independent laboratory.
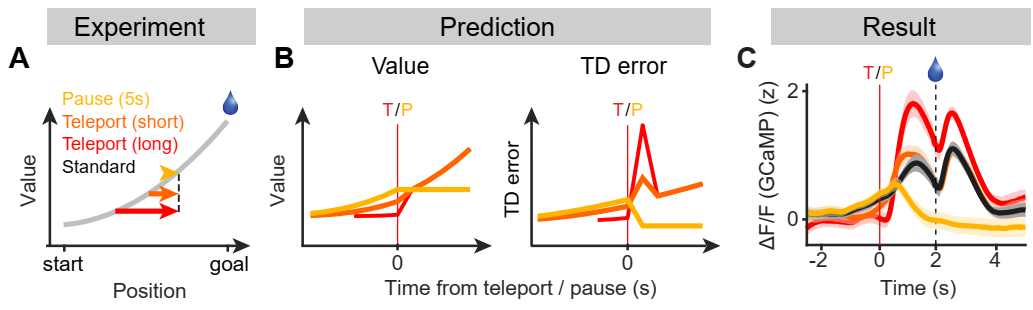
In conclusion, I showed slowly fluctuating dopamine ramping is a consequence of moment-by-moment TD error computation in dopamine neurons: the brain computes teaching signals in a way that truly resembles the one used in a machine learning theory.
For those who want to know more details about the results, video presentations would be helpful.