Research
Research overview
The Kim Lab at SKKU explores the neural mechanisms of motivated behavior and decision-making in uncertain environments. We focuses on how the cortical and subcortical circuits predict good and bad things and perform adaptive behaviors. We use a variety of experimental techniques as well as deep-learning simulations. By doing this, we hope to understand human nature, to help treat malfunctions of the brain, and to apply the principle of learning to improve artificial intelligence.
Diverse research topics in the lab can be represented in a four-dimensional space: 1) valence (good vs. bad), 2) timescale of activity (days of learning vs. seconds of dynamics), 3) normal brain vs. abnormal brain, and 4) focusing on biological brain (e.g., neural circuits) vs. computational principles.

- KSBNS 2024 NeuRLab abstracts, for those who want to peek ongoing works.
- A lab introduction interview on the SKKU webzine (Korean, posted 2023. 12. 22).
- Journal club and lab meeting list
How does the brain process reward and aversion information for adaptive behaviors?
We and all living animals can recognize what is good or bad for us and remember it. We then change our behavior to get more good things and avoid bad things. This looks like a very simple rule, but it is not always simple when situations become complex and uncertain. The brain has evolved to deal with these situations, and understanding it may provide insight into intelligence. Understanding the normal brain will give insights to deal with abnormal status of the brain pursuing reward (addiction) or avoiding aversiveness (post-traumatic stress disorder, PTSD).
How does internal state affect recognition of reward?
What drives behaviors? It’s some kind of recognition that we can obtain something ‘good’ in the future. How is the ‘goodness’ defined or formed in the brain? When you are thirsty, water is a great reward. When you are not thirsty, your body and brain do not want it anymore. It is an example that the pure value of external reward (e.g., water) is largely dependent on our bodily state, or internal state. Furthermore, for certain types of reward (e.g., sugar), our brain often cannot stop consuming even if our body does not need it, which leads people to obesity. We are interested in the underlying mechanisms of normal and abnormal mechanisms of recognizing and pursuing rewards.
What is it like the brain is addicted to something?
People often get addicted to something - e.g., sugar, a game, a smartphone, or drugs of abuse. When people get addicted to something, they keep doing specific behaviors despite the negative consequences of the actions. What makes the ‘addicted brain’ different from the normal brain? What are the underlying mechanisms of the dysregulated decision-making process? We hope to understand the underlying processes, so that we can provide useful knowledge to deal with it.
How to accurately decode ongoing brain activities?
Our major goal is to understand the meaning of brain activities. One of the promising applications is the brain-computer interface (BCI). We are developing frameworks for testing precise decoding of brain activities in mice and NHPs. We plan to devise algorithms for accurate decoding of ongoing brain activity that are fast, computationally efficient, and robust to representational drift.
Approaches
We use diverse experimental methods to obtain high-quality neural and behavior data. Then we use deep-learning models and computational tools to understand the complex patterns of data.
- 🐁 Cognitive tasks in virtual reality, augmented reality, and real environment enables us to put animals in a variety of vision-based task environments. Experimenters can have strong experimental control (e.g., teleporting animals to different positions) while animals perform semi-naturalistic tasks. We also use 🐵 Complex cognitive tasks for non-human primates in 2D or 3D environments, using joystick and/or eye movement as motor inputs.
 |
- 🐁🐵 Large-scale electrophysiological recording using Neuropixels enables us to record hundreds of single neurons in highest signal-to-noise ratio. We can hear the language of neurons - action potential - while monitoring behaviors simultaneously. We are developing closed-loop brain-computer interface (BCI) technology to reliably read out behaving animal’s mind real time.
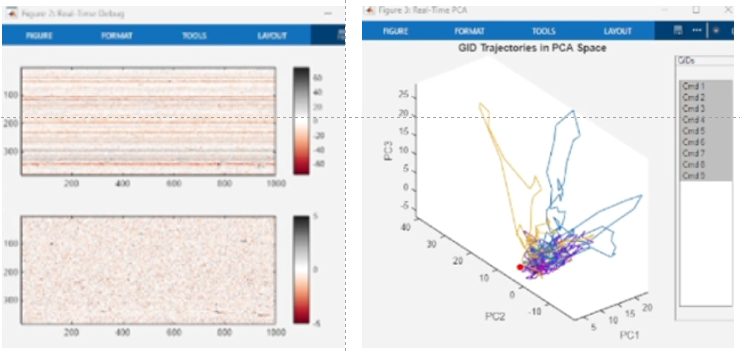 |
- 🐁 Cell-type-specific or target-specific optical monitoring using fiber photometry and miniscope are optical methods to monitor neural activity. Fiber photometry allows us to monitor pooled activity of neural responses in a axonal projection-specific manner. Miniscope enables us to monitor tens of single neurons in a cell type-specific manner. We also use 🐁 optogenetic or chemogenetic manipulations in rodents to study caucal relationship between brain activity and cognitive and behavioral processes.
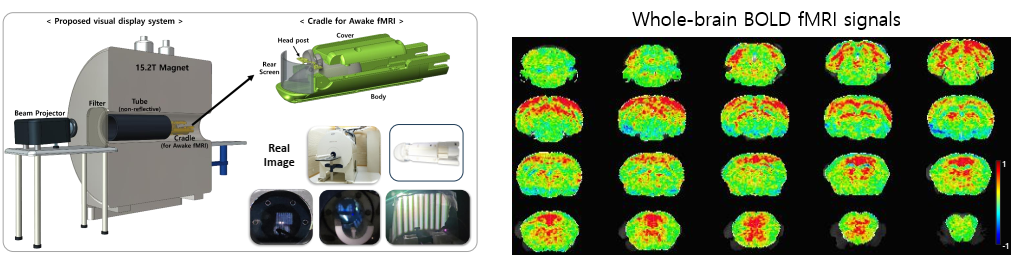
- 🐁 Ultra high-field fMRI imaging in awake mice enables us to monitor the activity of entire mouse brain. This provides us an opportunity to find new brain areas and analyze functional connectivity across brain areas.
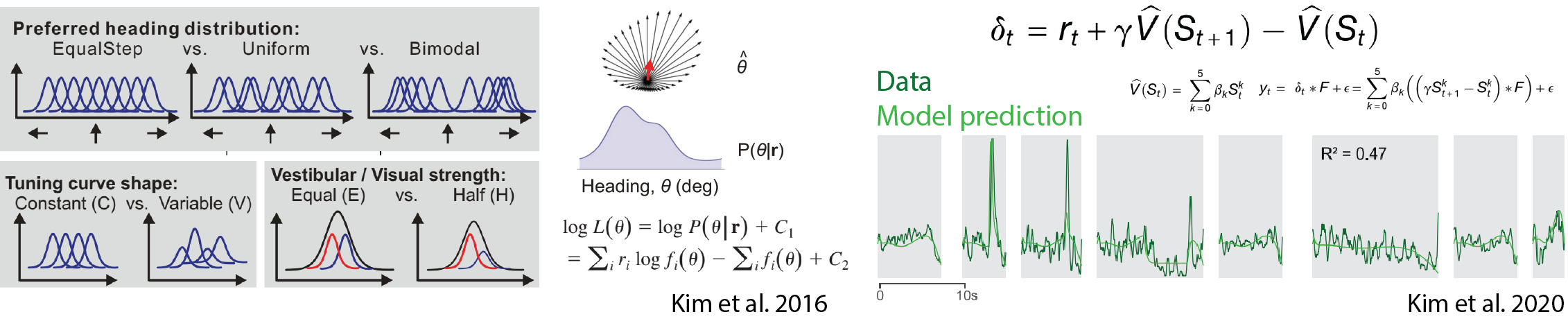
- 💻 Computational modeling is essential tools to understand complex brain activities from theoretical perspectives.
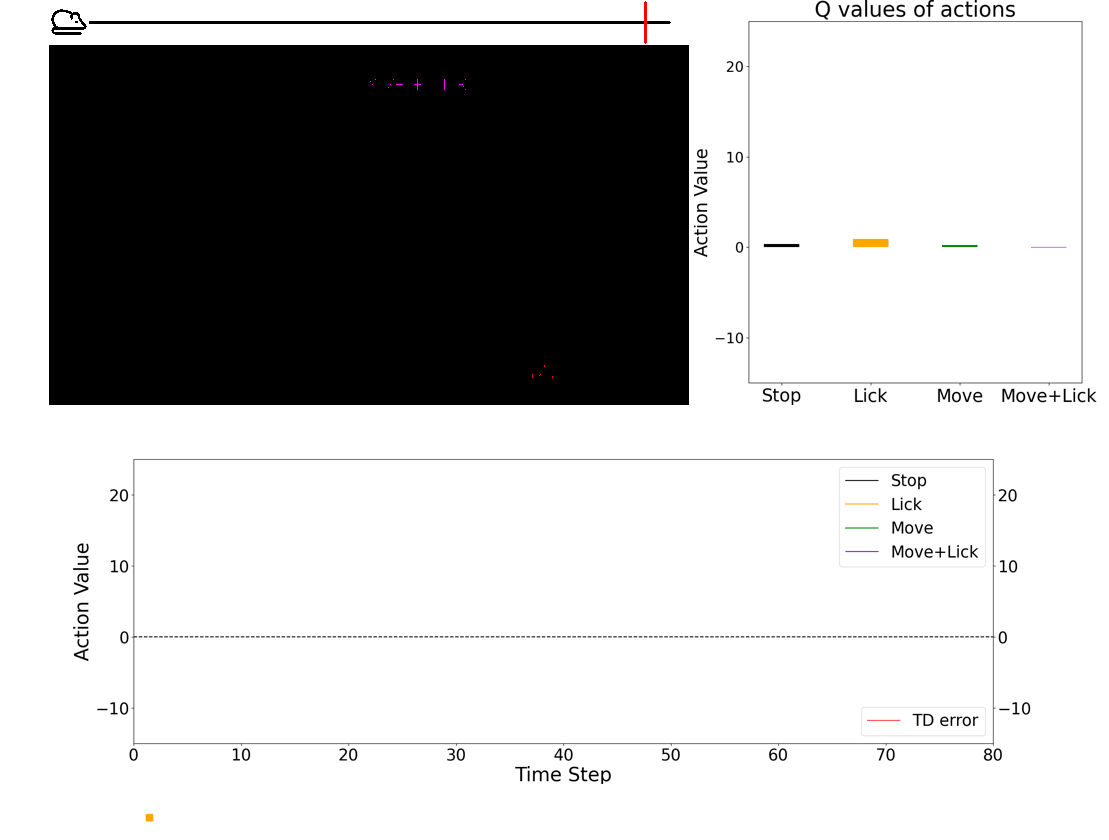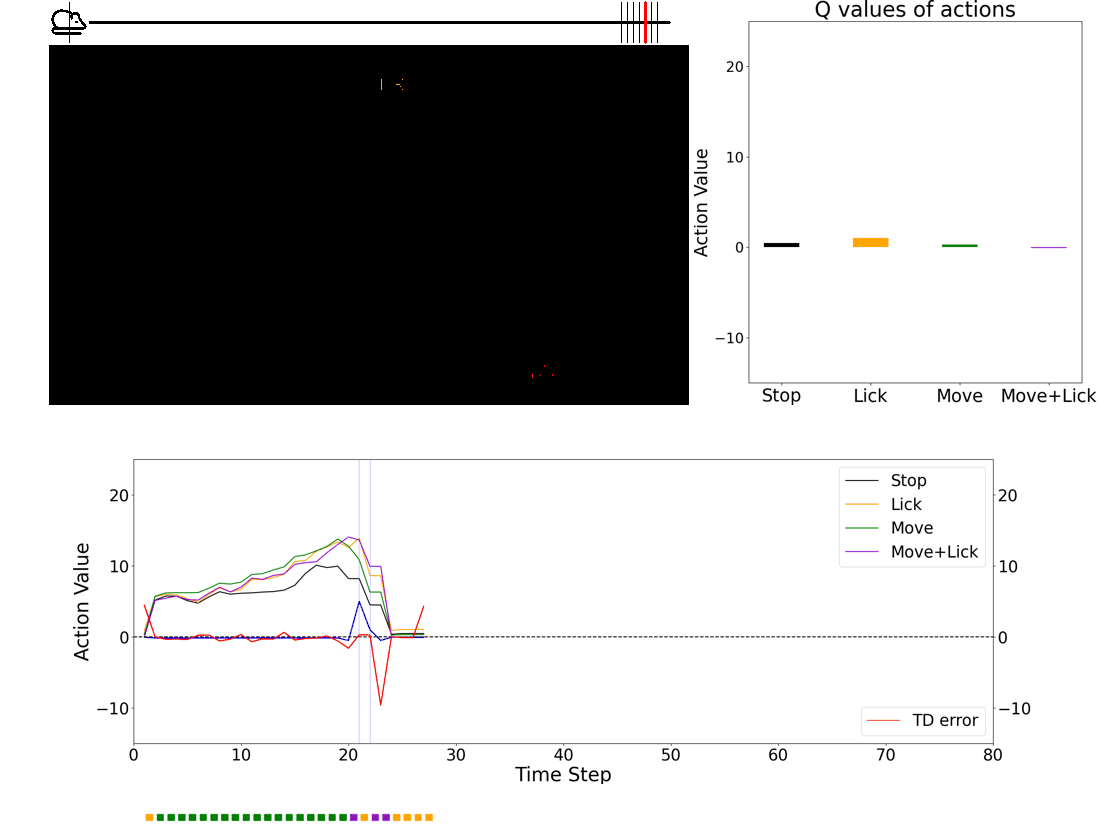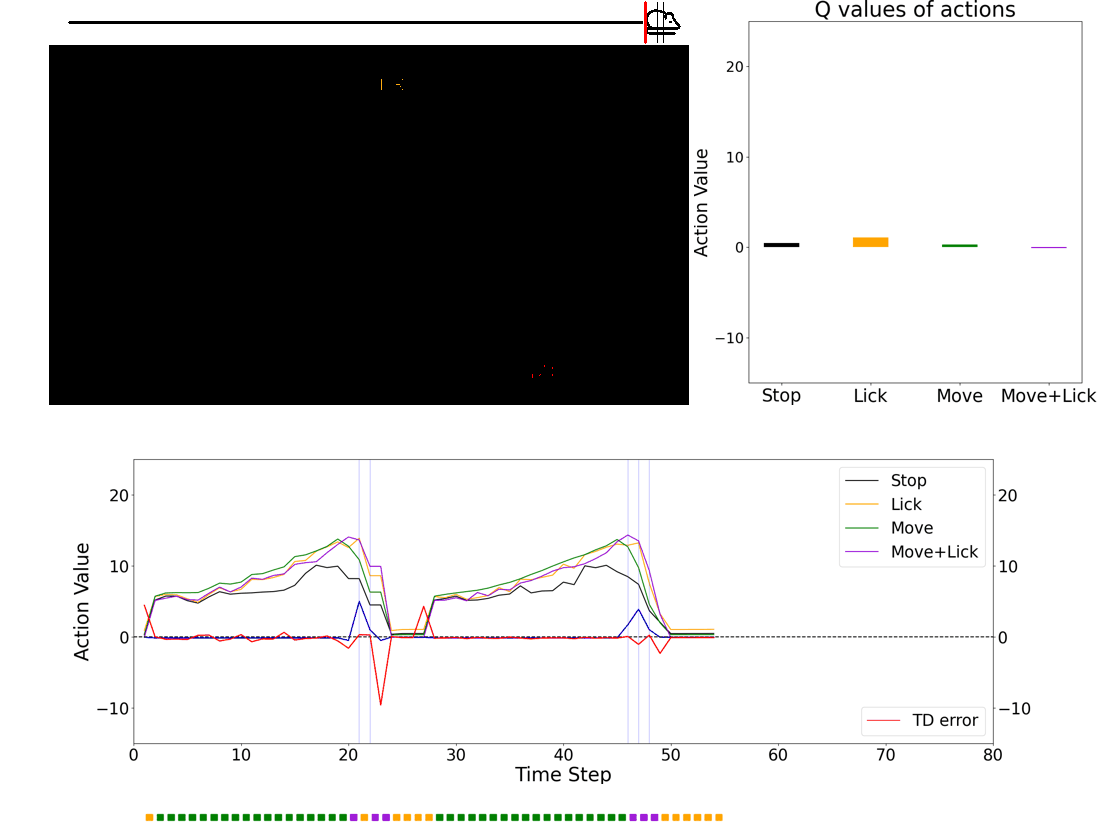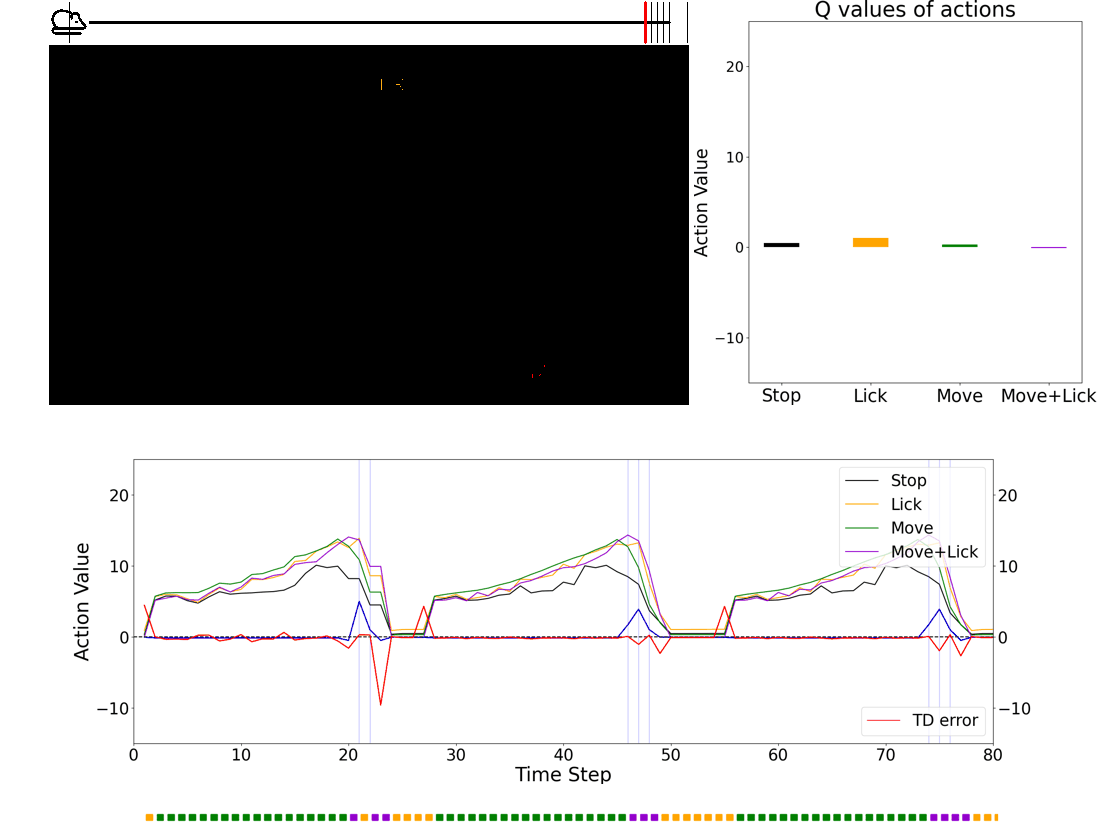
- 💻 Deep learning agent simulations provide critical insights on understanding how the brain performs behaviors. Especially, we have a framework in which we can train deep-learning agents using virtual reality experimental protocols identical to those we use for animal experiments. Using this framework, we can directly compare activities in the biological brain and artificial neural networks.
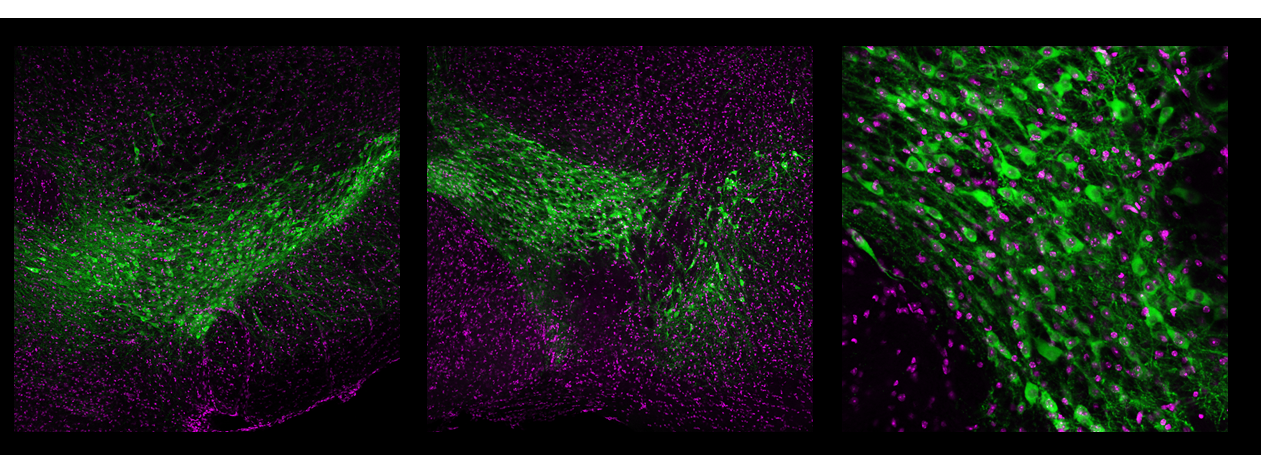
Dopamine neurons play important roles in learning, movtivation, and movement. Images courtesy of Ryu Amo.